<td id="alk0f"></td>
如若轉(zhuǎn)載,請(qǐng)注明出處:http://m.fanvff.cn/product/65.html
更新時(shí)間:2026-02-22 16:10:11
西北金峰雨衣注冊(cè)商標(biāo),申請(qǐng)人是誰(shuí)
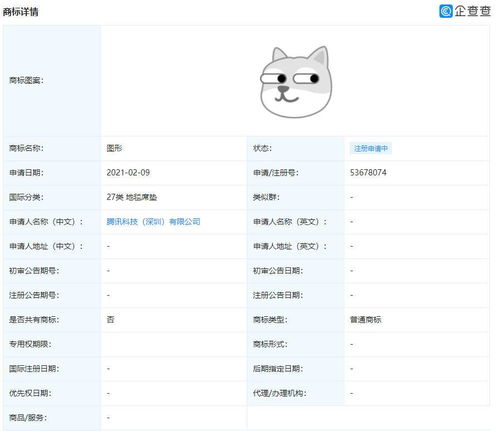
騰訊注冊(cè)狗頭商標(biāo)
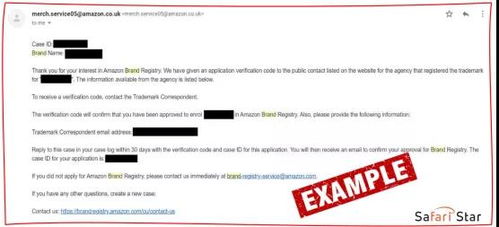
商標(biāo)注冊(cè) 亞馬遜品牌注冊(cè)流程
500億黃了 小霸王申請(qǐng)破產(chǎn)沒(méi)留下一個(gè)商標(biāo) 真 霸王別機(jī)
新世界產(chǎn)區(qū)中國(guó)煙臺(tái)獲地理標(biāo)志證明商標(biāo)
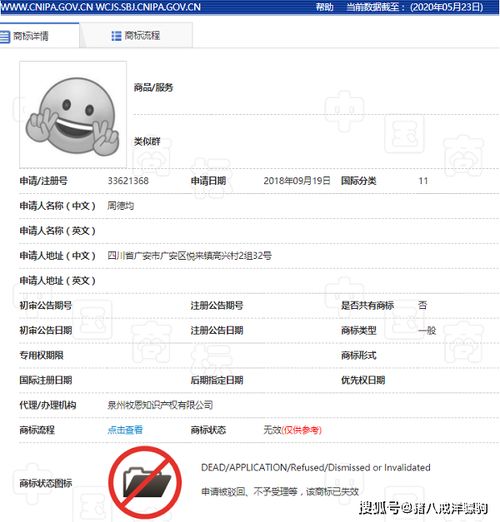
微信表情包又又又被申請(qǐng)注冊(cè)商標(biāo),騰訊又提出異議了
商標(biāo)注冊(cè)成功后,必須把r標(biāo)打上去嗎
中國(guó)成在歐商標(biāo)注冊(cè)量最大國(guó)家,為何歐盟商標(biāo)注冊(cè)受歡迎?
帥映科技新工廠在12月達(dá)到產(chǎn)量高峰_投影機(jī)-中國(guó)數(shù)字視聽(tīng)網(wǎng)
代工廠條形碼
電話:010-64018795
地址:北京市石景山區(qū)古城西路113號(hào)6層610室
Copyright © 2026 m.fanvff.cn 商標(biāo)申請(qǐng) 北京匯眾鵬博知識(shí)產(chǎn)權(quán)代理有限公司 商標(biāo)申請(qǐng) 版權(quán)所有 Sitemap